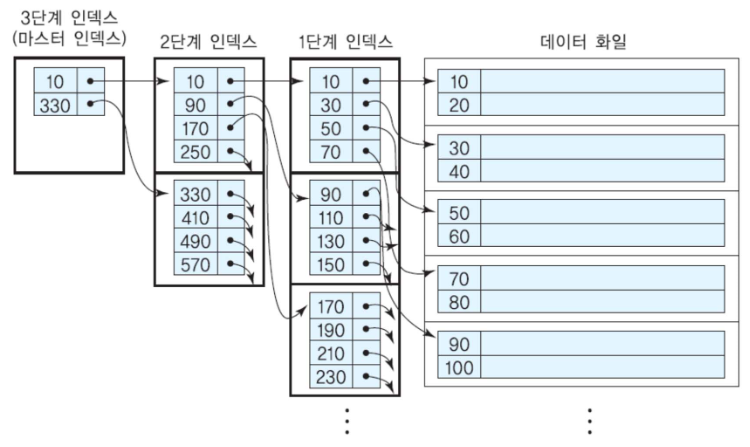
다단계 인덱스
인덱스 자체가 클 경우에는 인덱스를 탐색하는 시간도 오래 걸릴 수 있다.
인덱스 엔트리를 탐색하는 시간을 줄이기 위해서 단일 단계 인덱스를 디스크 상의 하나의 순서 화일로 간주하고, 단일 단계 인덱스에 대해서 다시 인덱스를 정의할 수 있다.
다단계 인덱스는 가장 상위 단계의 모든 인덱스 엔트리들이 한 블록에
들어갈 수 있을 때까지 이런 과정을 반복한다.
가장 상위 단계 인덱스를 마스터 인덱스 (master index)라고 부른다.
마스터 인덱스는 한 블록으로 이루어지기 때문에 주기억 장치에 상주할 수 있다.
대부분의 다단계 인덱스는 B+-트리를 사용한다

SQL의 인덱스 정의문
SQL의 CREATE TABLE문에서 PRIMARY KEY절로 명시한 애트리뷰트에 대해서는 DBMS가 자동적으로 기본 인덱스를 생성한다.
UNIQUE로 명시한 애트리뷰트에 대해서는 DBMS가 자동적으로 보조 인덱스를 생성한다.
SQL2는 인덱스 정의 및 제거에 관한 표준 SQL문을 제공하지 않는다.
다른 애트리뷰트에 추가로 인덱스를 정의하기 위해서는 DBMS마다 다소 구문이 다른 CREATE INDEX문을 사용해야 한다.
다수의 애트리뷰트를 사용한 인덱스 정의
한 릴레이션에 속하는 두 개 이상의 애트리뷰트들의 조합에 대하여 하나의 인덱스를 정의할 수 있다.
동등 조건에는 활용될 수 없다.
인덱스의 장점과 단점
인덱스는 검색 속도를 향상시키만 인덱스를 저장하기 위한 공간이 추가로 필요하고 삽입, 삭제, 수정 연산의 속도를 저하시킨다.
소수의 레코드들을 수정하거나 삭제하는 연산의 속도는 향상된다.
릴레이션이 매우 크고, 질의에서 릴레이션의 튜플들 중에 일부를 검색하고, WHERE절이 잘 표현되었을 때 특히 성능에 도움이 된다.
인덱스 선정 지침과 데이터베이스 튜닝
가장 중요한 질의들과 이들의 수행 빈도, 가장 중요한 갱신들과 이들의 수행 빈도, 이와 같은 질의와 갱신들에 대한 바람직한 성능들을 고려하여 인덱스를 선정한다.
워크로드 내의 각 질의에 대해 이 질의가 어떤 릴레이션들을 접근하는가, 어떤 애트리뷰트들을 검색하는가, WHERE절의 선택 / 조인 조건에 어떤 애트리뷰트들이 포함하는가, 이 조건들의 선별력은 얼마인가 등을 고려한다.
워크로드 내의 각 갱신에 대해 이 갱신이 어떤 릴레이션들을 접근하는가, WHERE절의 선택 / 조인 조건에 어떤 애트리뷰트들이 포함되는가, 이 조건들의 선별력은 얼마인가, 갱신의 유형 (INSERT / DELETE / UPDATE), 갱신의 영향을 받는 애트리뷰트 등을 고려함.
어떤 릴레이션에 인덱스를 생성해야 하는가, 어떤 애트리뷰트를 탐색 키로 선정해야 하는가, 몇 개의 인덱스를 생성해야 하는가, 각 인덱스에 대해 클러스터링 인덱스, 밀집 인덱스 / 희소 인덱스 중 어느 유형을 선택할 것인가 등을 고려함.
인덱스를 선정하는 한 가지 방법은 가장 중요한 질의들을 차례로 고려해보고, 현재의 인덱스가 최적의 계획에 적합한지 고려해보고, 인덱스를 추가하면 더 좋은 계획이 가능한지 알아본다.
물리적으로 데이터베이스 설계는 끊음없이 이루어지는 작업이다.
인덱스를 결정하는데 도움이 되는 몇 가지 지침
지침 1 : 기본 키는 클러스터링 인덱스를 정의할 훌륭한 후보
지침 2 : 외래 키도 인덱스를 정의할 중요한 후보
지침 3 : 한 애트리뷰트에 들어 있는 상이한 값들의 개수가 거의 전체 레코드 수와 비슷하고, 그 애트리뷰트가 동등 조건에 사용된다면 비 클러스터링 인덱스를 생성하는 것이 좋다.
지침 4 : 튜플이 많이 들어 있는 릴레이션에서 대부분의 질의가 검색하는 튜플이 2% ~ 4% 미만은 경우에는 인덱스를 생성한다.
지침 5 : 자주 갱신되는 애트리뷰트에는 인덱스를 정의하지 않는 것이 좋다.
지침 6 : 갱신이 빈번하게 이루어지는 릴레이션에는 인덱스를 많이 만드는 것을 피해야 한다.
지침 7 : 후보 키는 기본 키가 갖는 모든 특성을 마찬가지로 갖기 때문에 인덱스를 생성할 후보이다.
지침 8 : 인덱스는 화일의 레코드들을 충분히 분할할 수 있어야 한다.
지침 9 : 정수형 애트리뷰트에 인덱스를 생성
지침 10 : VARCHAR 애트리뷰트에는 인덱스를 만들지 않아야 한다.
지침 11 : 작은 화일에는 인덱스를 만들 필요가 없다.
지침 12 : 대량의 데이터를 삽입할 때는 모든 인덱스를 제거하고, 데이터 삽입이 끝난 후에 인덱스들을 다시 생성하는 것이 좋다.
인덱스가 사용되지 않는 경우
시스템 카탈로그가 오래 전의 데이터베이스 상태를 나타낼 때
DBMS의 질의 최적화 모듈이 릴레이션의 크기가 작아서 인덱스가 도움이 되지 않는다고 판단할 때
인덱스가 정의된 애트리뷰트에 산술 연산자가 사용될 때
DBMS가 제공하는 내장 함수가 사용될 때
널값에 대해서는 일반적으로 인덱스가 사용되지 않는다.
질의 튜닝을 위한 추가 지침
DISTINCT절의 사용을 최소화해야 함.
=> 중복 값을 제거하기 위해 정렬 또는 해싱 등 추가적인 작업이 필요함
GROUP BY절과 HAVING절의 사용을 최소화해야 함.
=> 시간이 오래 걸리는 작업
임시 릴레이션의 사용을 피해야 함.
=> 큰 질의를 임시 릴레이션을 사용하여 두 개 이상의 질의로 나누게 되면 각 질의에 대해 최적화가 이뤄져서 전체 질의를 최적화 한 것과 비교하여 성능이 나빠질 수 있음.
SELECT * 대신에 SELECT절에 애트리뷰트 이름들을 구체적으로 명시해야 함.
=> SELECT * 를 사용하게 되면 모든 애트리뷰트를 포함하기 때문에 불필요한 트래픽이 증가함.
'CS > DB' 카테고리의 다른 글
| [DB] 함수적 종속성 (0) | 2022.05.26 |
|---|---|
| [DB] 정규화 개요 (0) | 2022.05.26 |
| [DB] 화일 조직 (0) | 2022.05.19 |
| [DB] 물리적 데이터베이스 설계 (0) | 2022.05.16 |
| [DB] ER 스키마를 관계 모델의 릴레이션으로 사상하기 (1) | 2022.05.15 |